今天要來介紹強化學習中的一理論「馬可夫決策過程」(Markov Decision Process)
前幾天我們有提到增強式學習的主要元素包含:獎勵(reward)、訓練的對象(agent)、動作(actions)、 觀察(observations)、 環境(environment)
在馬可夫決策過程中,機器會進行一系列的動作;而每做一個動作、環境都會跟著發生變化。若環境的變化是離目標更接近、我們就會給予一個正向反饋(Positive Reward),比如當機器投籃時越來越接近籃框;若離目標更遠、則給予負向反饋(Negative Reward),比如賽車時機器越開越偏離跑道。
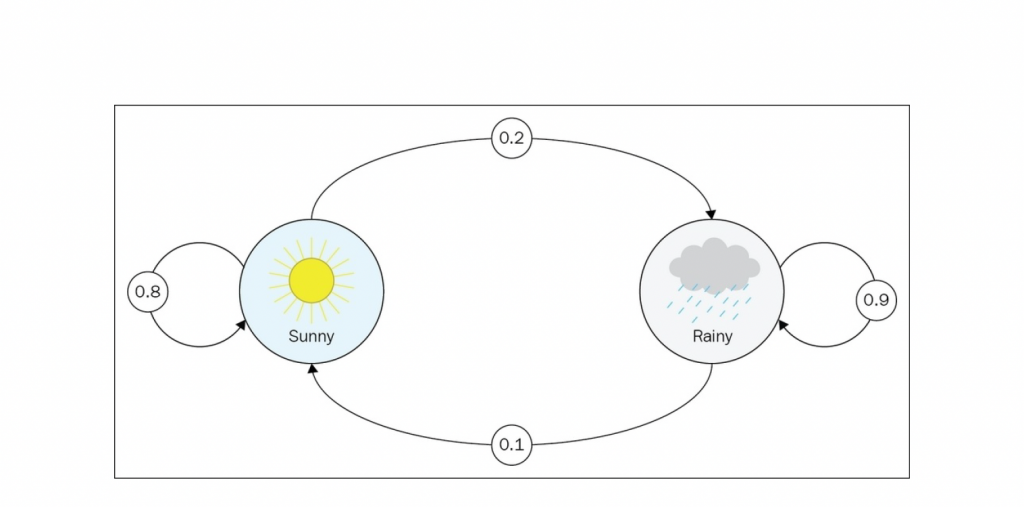
獎勵可以有多種形式。 最通用的方法是使用另一個類似於轉換矩陣的方陣,其中從狀態 i 轉換到狀態 j 的獎勵位於第 i 行和第 j 列。
獎勵可以是正的,也可以是負的,可以是大的,也可以是小的──它只是一個數字。 在某些情況下,這種表示是多餘的,可以簡化。 例如,如果無論之前的狀態如何,都會給予達到該狀態的獎勵,那麼我們可以只保留狀態→獎勵對,這是一種更緊湊的表示。

